索引の利用
索引(インデックス)は、索引キーとよばれる情報を物理的な格納位置と対応づけたもので、例えると本の目次のようなものです。
インデックスの効果は以下のような特徴を持つ表で特に現れやすいです。
・行数が多い
・検索対象の項目に値の重複、偏りが少ない
・表の更新・追加・削除が少ない
索引の仕組み
インデックスはデータ構造によっていくつかの種類があります。
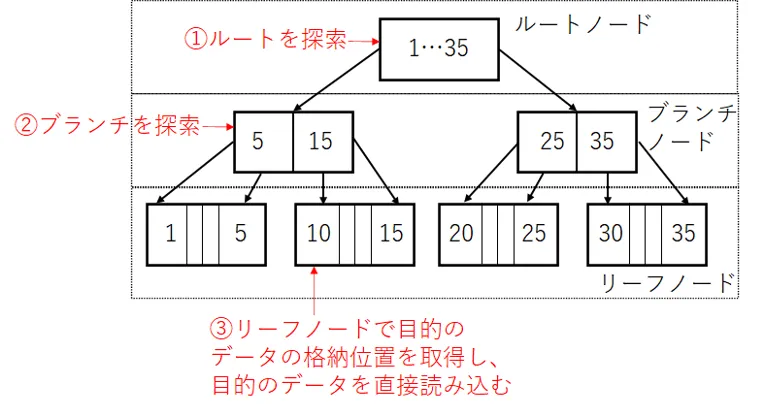
Bツリーインデックス(B+木索引)
Bツリーインデックスは木構造のインデックスです。もっとも一般的なインデックスのデータ構造です。Bツリーインデックスを用いると、「年齢が20以上30以下」のような、値の範囲を指定した検索において高い効果を発揮します。
ハッシュインデックス
ハッシュインデックスは、キー値をハッシュ関数でハッシュ化した値をレコードの住所としてデータを格納します。検索の際にはキー値をハッシュ化して導き出された場所に直接アクセスすることができます。
索引の欠点
索引の欠点は、データの追加・更新・削除時にオーバーヘッドが発生し、パフォーマンスが低下する可能性があることです。また、インデックス自体もストレージを消費し、不要なインデックスは逆に検索パフォーマンスを低下させる可能性があります。
再構成と再編成
データの追加・更新・削除といった操作を繰り返すと、データの格納効率が悪くなり、応答時間が悪化してしまいます。このような場合、無駄な空き領域をまとめて再利用するために再編成を行います。
これに対し、既存の表に列を追加するなど、現在のデータベースの構成を変更することを再構成とよびます。